16. Dez. 20251 min read
Von der Datenbank ins DOM: Die Architektur einer skalierbaren Career-Page-Engine auf Google Cloud
Client WorkDaily InsightsPage Generator+5
In der modernen Personalvermittlung reicht es nicht mehr aus, Lebensläufe (CVs) einfach nur in einem Ordner zu speichern. Die Herausforderung besteht darin, unstrukturierte Daten (PDFs, Word-Dokumente) in strukturierte Insights zu verwandeln und diese in Millisekunden durchsuchbar zu machen.Dec 20, 2025
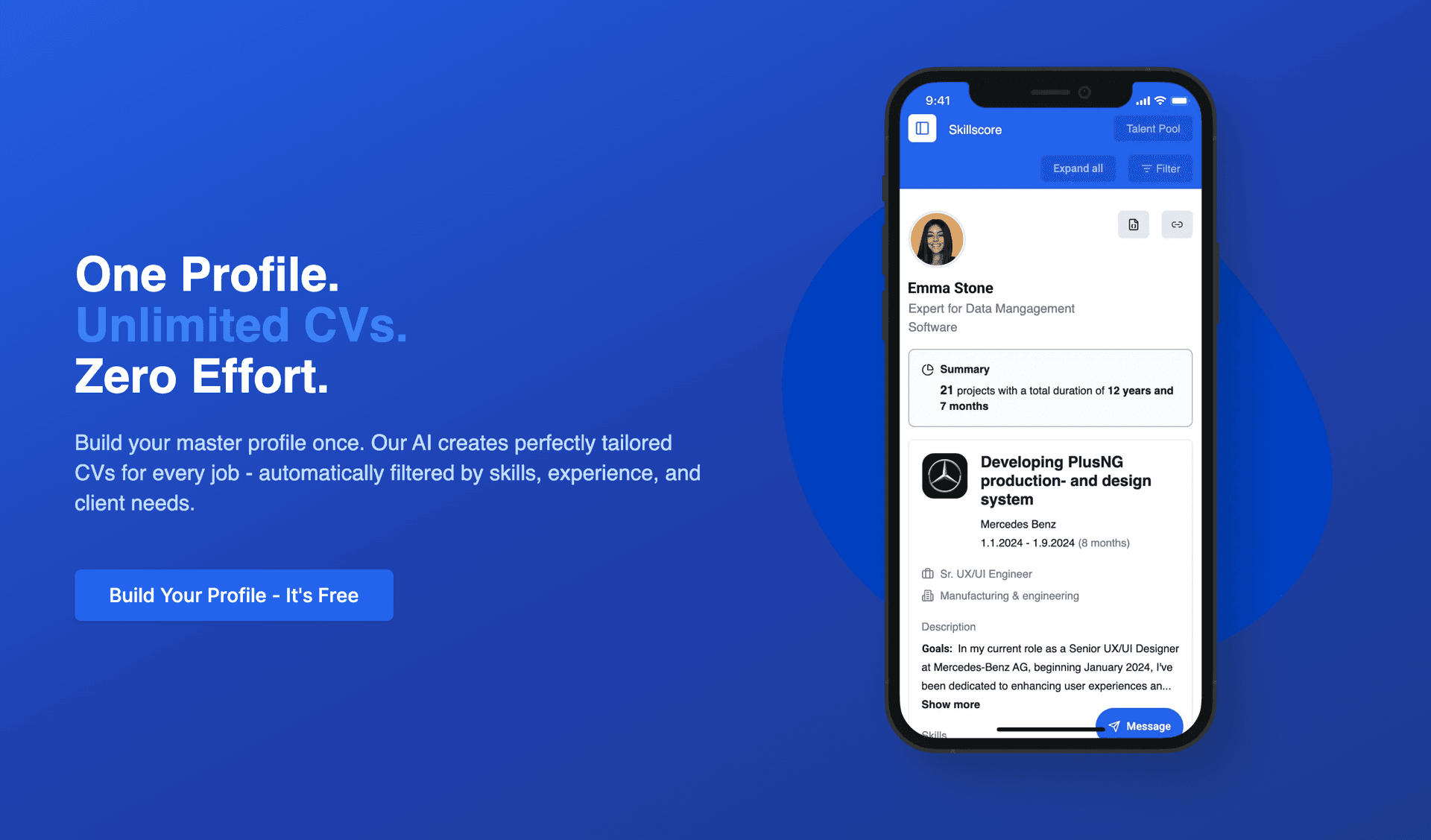
In diesem Artikel tauchen wir in den Tech-Stack und die Architektur von SkillScore ein – einer Enterprise-Grade API, die ich entwickelt habe, um genau dieses Problem zu lösen. Wir betrachten, wie man mit NestJS, MongoDB, Redis, WebSockets und OpenAI (GPT-4) eine skalierbare Backend-Infrastruktur baut.
Hier geht es zur Swagger UI API Dokumentation
Bevor wir tief in die Code-Implementierung eintauchen, hier ein kompakter Überblick über die architektonischen Services und den Technologie-Stack, der SkillScore antreibt.
Dieses Projekt vereint komplexe Backend-Disziplinen zu einer nahtlosen Plattform:
Das Herzstück unserer Plattform ist eine monolithische (aber modular aufgebaute) Architektur basierend auf NestJS. NestJS wurde gewählt, weil es durch seine starke Strukturierung (Module, Controller, Services) und die native Unterstützung von TypeScript perfekt für Enterprise-Anwendungen geeignet ist.
@aws-sdk/client-s3).Unser Stack setzt auf Typensicherheit, Skalierbarkeit und moderne Cloud-Native Tools:
Development Core
Nest.js • TypeScript • MongoDB • Redis • Bull Queue • AWS S3 • Docker • JWT • Jest • REST API
Ecosystem & Integrations
Socket.io • OpenAI API • OAuth2 • Swagger • GitHub Actions • Heroku • WebSockets • Microservices
Die AppModule Konfiguration zeigt, wie modular das System aufgebaut ist. Wir trennen strikt nach Domänen (Projects, Users, Skills, Jobs), was die Wartbarkeit bei über 50 Endpoints garantiert.
// app.module.ts (Auszug)
@Module({
imports: [
ConfigModule.forRoot({ isGlobal: true }),
// Redis Konfiguration für Caching und Queues
CacheModule.register({ store: redisStore, ... }),
BullModule.forRoot({ ... }),
MongooseModule.forRoot(process.env.MONGODB_URI),
// Feature Modules
AuthModule,
UsersModule,
CVUploadModule, // Der Core der CV Verarbeitung
AIExtractionModule, // GPT-4 Integration
SkillMatchingModule,// Fuzzy Logic Engine
// ... 20+ weitere Module
],
controllers: [AppController],
providers: [], // Global Guards werden hier registriert
})
export class AppModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer.apply(RequestLoggerMiddleware).forRoutes('*');
}
}
Sicherheit ist kein Feature, sondern die Basis. Bevor ein einziger CV hochgeladen wird, muss der Request authentifiziert und autorisiert werden. Wir nutzen Passport.js mit JWTs (JSON Web Tokens).
Ein Blick in unsere Dateistruktur (guards.png) zeigt eine feingranulare Aufteilung der Guards. Wir verlassen uns nicht nur auf einen globalen Guard, sondern haben spezifische Wächter für API-Keys, Admin-Rechte und Refresh-Token-Logik.
Die Ordnerstruktur:
guards/
├── accessToken.guard.ts # Standard JWT Schutz
├── admin.guard.ts # Nur für User mit Role 'admin'
├── apiKey.guard.ts # Für Server-to-Server Kommunikation
├── recruiter.guard.ts # Speziell für Recruiter-Zugriffe
└── refreshToken.guard.ts # Für die Token-Erneuerung
Der AccessTokenGuard ist unsere erste Verteidigungslinie. Er erweitert den Standard AuthGuard('jwt') von NestJS, fügt aber entscheidendes Logging hinzu. Wenn ein Token ungültig ist, wollen wir genau wissen, warum (abgelaufen? falsche Signatur?).
// access-token.guard.ts
@Injectable()
export class AccessTokenGuard extends AuthGuard('jwt') {
private readonly logger = new Logger(AccessTokenGuard.name);
canActivate(context: ExecutionContext) {
// Logging vor der Validierung
return super.canActivate(context);
}
handleRequest(err, user, info, context: ExecutionContext) {
// Custom Error Handling
if (err || !user) {
this.logger.error(`JWT validation failed: ${info?.message}`);
throw err || new UnauthorizedException('Invalid token');
}
return user;
}
}
Dazu passend definiert die Strategie, wie das Token validiert wird. Wir extrahieren das Token aus dem Authorization: Bearer Header. Wichtig: Wir speichern keine sensiblen Daten im Token, nur die userId (sub) und die role.
// access-token.strategy.ts
@Injectable()
export class AccessTokenStrategy extends PassportStrategy(Strategy, 'jwt') {
constructor(config: ConfigService) {
super({
jwtFromRequest: ExtractJwt.fromAuthHeaderAsBearerToken(),
secretOrKey: config.get<string>('JWT_SECRET'),
ignoreExpiration: false,
});
}
validate(payload: JwtPayload) {
// Der Rückgabewert wird an request.user angehängt
return {
userId: payload.sub,
email: payload.email,
role: payload.role
};
}
}
Durch die Kombination von Guards und Strategien können wir Endpoints sehr deklarativ schützen:
@UseGuards(AccessTokenGuard, RolesGuard)
@Roles('admin', 'recruiter')
@Post('upload')
uploadCV(...) { ... }
Warum MongoDB? CV-Daten sind von Natur aus hierarchisch und oft unvollständig. Ein Kandidat hat vielleicht "Skills", ein anderer "Zertifikate", ein dritter "Publikationen". Ein starres SQL-Schema würde hier zu vielen NULL-Spalten oder komplexen Join-Tabellen führen.
Unsere Schema-Struktur (schemas.png) zeigt, wie stark normalisiert wir trotz NoSQL arbeiten, um Datenintegrität zu wahren.
Ein besonderes Augenmerk liegt auf dem Skill Schema. Um Duplikate wie "React", "React.js" und "ReactJS" zu vermeiden, nutzen wir Normalisierung und Aliases.
// schemas/skill.schema.ts (Konzept)
@Schema({ timestamps: true })
export class Skill {
@Prop({ required: true, unique: true })
name: string; // Display Name: "React"
@Prop({ required: true, index: true })
normalizedName: string; // "react"
@Prop([String])
aliases: string[]; // ["reactjs", "react.js"]
@Prop({ type: String, enum: ['frontend', 'backend', 'devops'] })
category: string;
@Prop({ type: [{ type: mongoose.Schema.Types.ObjectId, ref: 'Skill' }] })
relatedSkills: Skill[]; // Graph-ähnliche Beziehungen
}
Diese Struktur ermöglicht es uns später, bei der Suche nach "Javascript" auch Kandidaten zu finden, die "TypeScript" oder "ECMAScript" angegeben haben, indem wir die relatedSkills traversieren.
Ein Applicant Tracking System (ATS) ist nur so gut wie seine Datenstruktur. Das größte Problem bei der Verarbeitung von CVs ist die Varianz menschlicher Eingaben. Ein Kandidat schreibt "ReactJS", ein anderer "React.js", ein dritter nur "React".
Für eine naive Datenbankabfrage sind das drei völlig unterschiedliche Dinge. Das Ergebnis? Unvollständige Suchergebnisse und frustrierte Recruiter.
Unsere Architektur behandelt Skills nicht als Strings, sondern als Entitäten. Unser Ziel ist es, jeden noch so chaotischen Input auf einen eindeutigen MongoDB ObjectId Hash zu mappen. Nur so erreichen wir die Filterbarkeit eines CRM/ERP-Systems:
65a1...65b2...Um dies zu erreichen, haben wir eine mehrstufige Hybrid-Matching-Engine entwickelt, die Geschwindigkeit (Fuse.js) mit mathematischer Präzision (Levenshtein) kombiniert.
Bevor wir komplexe Algorithmen anwenden, bereinigen wir die Daten. Unser SkillMatchingService normalisiert Inputs aggressiv, um Trivialitäten (Groß-/Kleinschreibung, Sonderzeichen) zu eliminieren.
// src/skills/skill-matching.service.ts
private normalizeSkillName(name: string): string {
return name
.toLowerCase()
.trim()
.replace(/[^\w\s]/g, '') // Entfernt Punkte aus "Node.js" -> "nodejs"
.replace(/\s+/g, ' '); // Normalisiert Whitespace
}
Wir können nicht für jeden Request die Levenshtein-Distanz gegen 10.000 Datenbank-Einträge berechnen – das wäre zu langsam. Deshalb nutzen wir einen 3-Stufen-Ansatz:
Hier ist die Implementierung der Kern-Logik:
// src/skills/skill-matching.service.ts
async findBestMatch(skillName: string): Promise<SkillMatch[]> {
// Performance: Cache Update Strategie (Refresh alle 5 Min)
await this.updateSkillCache();
const normalizedInput = this.normalizeSkillName(skillName);
const matches: SkillMatch[] = [];
// SCHRITT 1: Exakter Match (Fast Path)
const exactMatch = this.skillCache.find(
(skill) => this.normalizeSkillName(skill.name) === normalizedInput,
);
if (exactMatch) {
return [{
_id: exactMatch._id.toString(),
name: exactMatch.name,
score: 1.0, // 100% Match
distance: 0,
}];
}
// SCHRITT 2: Fuse.js Vorauswahl
// Wir nutzen Fuse, um den Suchraum drastisch zu verkleinern
if (this.fuseInstance) {
const fuseResults = this.fuseInstance.search(skillName, { limit: 5 });
for (const result of fuseResults) {
// SCHRITT 3: Levenshtein Präzisions-Berechnung
const distance = levenshtein(
normalizedInput,
this.normalizeSkillName(result.item.name),
);
// Berechnung des finalen Scores
const score = this.calculateMatchScore(
skillName,
result.item.name,
result.score || 0,
distance,
);
// Nur Matches mit hoher Wahrscheinlichkeit zulassen (>50%)
if (score > 0.5) {
matches.push({
_id: result.item._id.toString(), // Die "Golden Source" ID
name: result.item.name,
score,
distance,
});
}
}
}
// Sortieren nach Score (bester Match zuerst)
return matches.sort((a, b) => b.score - a.score);
}
Warum reicht Fuse.js allein nicht? Weil es manchmal zu "gütig" ist. Wir gewichten daher die Ergebnisse. Unser Algorithmus kombiniert den Pattern-Matching-Score von Fuse mit der strikten Edit-Distanz von Levenshtein.
// src/skills/skill-matching.service.ts
private calculateMatchScore(
input: string,
target: string,
fuseScore: number,
distance: number,
): number {
const maxLength = Math.max(input.length, target.length);
// Distanz-Score: Wie viele Buchstaben müssen geändert werden?
const distanceScore = 1 - distance / maxLength;
// Gewichtung:
// 60% Pattern Match (Fuse) - gut für Teiltreffer
// 40% Edit Distance (Levenshtein) - gut gegen Tippfehler
const combinedScore = (1 - fuseScore) * 0.6 + distanceScore * 0.4;
return Math.max(0, Math.min(1, combinedScore));
}
Oft scheitert das Matching an simpler Grammatik. "Senior Developer" vs "Senior Developers". Unser SkillsService antizipiert diese Variationen, bevor überhaupt die Datenbank gefragt wird.
// src/skills/skills.service.ts
private getNameVariations(normalizedName: string): string[] {
const variations = [];
// Intelligente Plural/Singular Erkennung
if (normalizedName.endsWith('s')) {
// "Developers" -> "Developer"
variations.push(normalizedName.slice(0, -1));
} else {
// "Developer" -> "Developers"
variations.push(normalizedName + 's');
}
// Spezialfälle wie "Companies" vs "Company"
if (normalizedName.endsWith('ies')) {
variations.push(normalizedName.slice(0, -3) + 'y');
} else if (normalizedName.endsWith('y')) {
variations.push(normalizedName.slice(0, -1) + 'ies');
}
return variations.map((v) => normalizeSkillName(v));
}
Durch diesen enormen Aufwand stellen wir sicher, dass in der Datenbank saubere Hash Relations entstehen.
Wenn ein User nach "JS" sucht, findet unser System über Aliases und Relationen (definiert im NlpSkillService) automatisch Kandidaten mit "JavaScript", "ECMAScript" oder "Node.js". Das System verhält sich nicht wie eine dumme Suchmaske, sondern wie ein intelligenter Assistent, der den Kontext versteht.
Dies ist der Unterschied zwischen einer simplen Mongo-Datenbank und einer ATS-optimierten Plattform.
Das technisch anspruchsvollste Modul ist CVUploadModule. Hier passiert die Magie: Ein unstrukturiertes PDF wird in JSON verwandelt. Dieser Prozess muss asynchron ablaufen, da GPT-4 und OCR Zeit benötigen. Wir wollen den HTTP-Request des Users nicht blockieren.
cv-processing Queue (Redis/Bull) geschoben.Das CVUploadModule importiert alle notwendigen Services und registriert die Queues.
// cv-upload.module.ts
@Module({
imports: [
// Registrierung der Worker-Queue
BullModule.registerQueue({ name: 'cv-processing' }),
MongooseModule.forFeature([{ name: CVUpload.name, schema: CVUploadSchema }]),
FileUploadModule, // S3 Logic
AIExtractionModule, // GPT-4 Logic
SkillMatchingModule, // Fuzzy Logic
],
controllers: [CVUploadController],
providers: [
CVUploadService,
CVUploadGateway, // WebSocket
CVUploadProcessor, // Der Bull Consumer (Worker)
],
})
export class CVUploadModule {}
Wir verlassen uns nicht blind auf GPT-4, da dies teuer und manchmal langsam ist. Wir nutzen einen hybriden Ansatz: Erst parst ein lokaler Algorithmus (basierend auf OpenResume) die Struktur. GPT-4 wird dann genutzt, um Kontext zu verstehen (z.B. "Ist 'Java' hier die Sprache oder die Insel?") und Daten zu normalisieren.
// ai-extraction.service.ts
async extractWithAI(cvText: string): Promise<ExtractedData> {
// Schritt 1: Lokaler Parser (schnell, grob)
const baseData = await this.openResumeParser.parse(cvText);
// Schritt 2: GPT-4 Enhancement (intelligent)
const prompt = `
Analysiere den folgenden CV-Text.
Extrahiere Skills, Erfahrung in Jahren und Projekte.
Transformiere das Ergebnis in folgendes JSON Format: ${JSON_SCHEMA}.
Nutze die Basis-Daten als Referenz: ${JSON.stringify(baseData)}
`;
const completion = await this.openai.chat.completions.create({
model: 'gpt-4-turbo',
messages: [{ role: 'user', content: prompt }],
response_format: { type: 'json_object' }, // Garantiert valides JSON
});
return JSON.parse(completion.choices[0].message.content);
}
Dieser Service extrahiert nicht nur, er interpretiert. Wenn im CV steht "Verantwortlich für das Frontend Deployment", erkennt die AI Skills wie "CI/CD", "Docker" oder "Netlify", auch wenn diese Worte nicht explizit fallen.
Daten zu haben ist gut, sie zu matchen ist besser. Ein Recruiter sucht nach "NodeJS", der Kandidat hat "Node.js" im Profil. Ein exakter String-Vergleich (===) würde hier versagen.
Wir nutzen den Levenshtein-Distanz-Algorithmus und normalisierte Strings im SkillMatchingService.
Der Service lädt alle bekannten Skills aus der DB (gecached via Redis) und vergleicht die extrahierten Skills aus dem CV damit.
// nlp.service.ts / skill-matching.service.ts
normalizeSkillName(name: string): string {
// Entfernt Sonderzeichen, lowercase
return name.toLowerCase().replace(/[^a-z0-9]/g, '');
}
calculateSimilarity(s1: string, s2: string): number {
const norm1 = this.normalizeSkillName(s1);
const norm2 = this.normalizeSkillName(s2);
const distance = levenshtein(norm1, norm2); // Externe Library oder Utility
const maxLength = Math.max(norm1.length, norm2.length);
return 1 - (distance / maxLength); // Gibt % Übereinstimmung zurück (0.0 bis 1.0)
}
async matchSkills(extractedSkills: string[]) {
const dbSkills = await this.skillModel.find().lean();
return extractedSkills.map(extracted => {
// Finde den besten Match in der DB
const bestMatch = dbSkills.reduce((best, current) => {
const score = this.calculateSimilarity(extracted, current.name);
return score > best.score ? { skill: current, score } : best;
}, { skill: null, score: 0 });
// Threshold: Nur Matches über 85% gelten als Treffer
if (bestMatch.score > 0.85) {
return { original: extracted, matchedId: bestMatch.skill._id, score: bestMatch.score };
}
return { original: extracted, matchedId: null, isNew: true };
});
}
Das Ergebnis: Wir speichern in der Datenbank Referenzen auf valide Skill-IDs, nicht nur Strings. Das macht spätere Analytics ("Wie viele React-Entwickler haben wir?") trivial.
Warum betreiben wir diesen immensen Aufwand mit Hashes, Normalisierung und Linked Data? Die Antwort liegt in der Analysierbarkeit.
In klassischen Systemen ist ein CV ein statisches Dokument. In SkillScore ist ein CV ein lebendiges Daten-Objekt, das wir in Echtzeit gegen Anforderungen "evaluieren" können. Weil jede Entität (Skill, Kunde, Industrie) eine eindeutige ObjectId besitzt, können wir mathematische Operationen auf Erfahrungen anwenden.
Wir nennen das "Evaluated Data". Statt dem Recruiter nur zu sagen "Hier ist ein Profil", liefern wir ein fertiges Analyse-Objekt mit Scores, Gaps und exakten Zeitberechnungen.
Da "React" bei uns immer die ID 507f1f77bcf86cd799439011 ist (egal ob der User "React.js" oder "reactjs" eingab), können wir Aggregationen fahren, die bei Textfeldern unmöglich wären:
Automotive (ID: 609b...) Industrie verbracht."Unsere API liefert für jedes Profil ein komplexes evaluation Objekt. Hier berechnen wir nicht nur ob ein Skill vorhanden ist, sondern wie tief die Erfahrung geht.
Hier ein Beispiel aus der API-Response für einen Senior Developer:
// GET /profiles/{id}/evaluation
{
"matchScore": 94, // Globaler Score basierend auf allen Filtern
"experienceBreakdown": {
"skills": {
"507f1f77bcf86cd799439011": { // Hash für "TypeScript"
"name": "TypeScript",
"duration": 1489, // Exakte Tage aus allen Projekten summiert
"formatted": "4 years 1 month",
"score": 100, // 100% Score da > geforderte 2 Jahre
"minRequiredDays": 730,
"meetsMinRequirement": true,
"proficiencyMultiplier": 1.0 // Täglicher Einsatz im Projekt
}
},
"industries": {
"609b2...": {
"name": "Finance",
"duration": 730,
"formatted": "2 years"
}
}
}
}
Die Berechnung dieser Daten geschieht "On-the-Fly" mithilfe von MongoDB Aggregation Pipelines und TypeScript-Logik. Wir berücksichtigen dabei sogar die Nutzungsintensität (Proficiency).
War ein Skill in einem Projekt nur "Nebensache" (z.B. monatliche Nutzung), zählt die Zeit nur zu 5%. War es "Daily Business", zählt sie zu 100%.
// src/profiles/profile-evaluation.service.ts
calculateExperienceScore(
actualDays: number,
requiredDays: number,
proficiency: 'daily' | 'weekly' | 'monthly'
): number {
// 1. Proficiency Gewichtung anwenden
const multipliers = {
daily: 1.0,
weekly: 0.2, // Zählt nur zu 20%
monthly: 0.05 // Zählt nur zu 5%
};
const weightedDays = actualDays * multipliers[proficiency];
// 2. Base Calculation (Linear Scaling)
// 1 Jahr Erfahrung = 100 Basispunkte (Skalierbar)
let score = (weightedDays / 365) * 100;
// 3. Requirement Capping
if (requiredDays > 0) {
// Wenn Requirement nicht erfüllt, Score hart auf 50% cappen
if (weightedDays < requiredDays) {
score = Math.min(50, (weightedDays / requiredDays) * 100);
}
}
return Math.round(score);
}
Ein weiteres Power-Feature, das nur durch Hash-Relations möglich ist, ist das Client-Filtering. Ein Recruiter kann fragen: "Zeige mir Kandidaten, die schon mal für BMW oder Audi gearbeitet haben."
Da "BMW" als Client-Hash ClientDocument existiert und Projekte mit diesem Hash verlinkt sind, ist diese Abfrage extrem performant und präzise – im Gegensatz zu einer Volltextsuche, die auch Kandidaten finden würde, die "Ich fahre gerne BMW" in ihre Bio schreiben.
Das Ergebnis: Wir verwandeln unstrukturierte Bewerberdaten in ein Data Warehouse für Talente. Das macht SkillScore nicht nur zu einer Suchmaschine, sondern zu einem Decision-Support-System.
Niemand starrt gerne auf einen Ladebalken, der sich nicht bewegt. Da unser CV-Processing im Hintergrund (Worker) läuft, müssen wir das Frontend proaktiv informieren. Polling (alle 2 Sekunden fragen "Bist du fertig?") ist ineffizient.
Wir nutzen Socket.io über das @nestjs/websockets Modul.
Das Gateway authentifiziert die WebSocket-Verbindung (ja, auch WebSockets brauchen JWTs!) und managed "Rooms". Jeder User bekommt einen eigenen Room (user:123), damit er nur seine eigenen Updates sieht.
// cv-upload.gateway.ts
@WebSocketGateway({
namespace: 'cv-upload',
cors: { origin: '*' } // In Production einschränken!
})
export class CVUploadGateway implements OnGatewayConnection {
@WebSocketServer() server: Server;
async handleConnection(client: Socket) {
try {
// JWT aus dem Handshake extrahieren & validieren
const token = client.handshake.auth.token;
const user = await this.authService.validateToken(token);
// Client in User-spezifischen Room joinen
client.join(`user:${user.id}`);
console.log(`User ${user.id} connected for realtime updates`);
} catch (e) {
client.disconnect();
}
}
// Wird vom Worker-Service aufgerufen
notifyProgress(userId: string, progress: number, stage: string) {
this.server.to(`user:${userId}`).emit('uploadProgress', {
progress,
stage, // z.B. "AI Extraction", "Virus Scan", "Saving"
timestamp: new Date()
});
}
}
Wenn der Bull-Worker einen Schritt abschließt (z.B. "Virus Scan complete"), emittet er ein Event, das dieses Gateway aufruft. Der User sieht im Frontend sofort den Fortschritt.
Bei Tausenden von Profilen und komplexen Suchfiltern ("Suche Dev mit React > 3 Jahre UND (NodeJS ODER Python)") wird die Datenbank stark belastet.
Statt einfacher .find() Queries nutzen wir mächtige Aggregation Pipelines. Diese berechnen Matches direkt auf der Datenbank-Ebene, statt Daten erst in Node.js zu laden und dort zu filtern.
Ein Beispiel aus dem projects-lookup.service.ts für die Talent-Suche:
// aggregation-pipeline.ts (Auszug)
const pipeline = [
// 1. Filter: Nur relevante Profile
{ $match: { isPublic: true, status: 'active' } },
// 2. Lookup: Verknüpfe Skills (Foreign Key in Mongo)
{
$lookup: {
from: 'skills',
localField: 'skills.skillId',
foreignField: '_id',
as: 'skillDetails'
}
},
// 3. Scoring: Berechne Match-Score (dynamisch!)
{
$addFields: {
matchScore: {
$divide: [
{ $size: { $setIntersection: ['$skills.skillId', requiredSkillIds] } },
requiredSkillIds.length
]
}
}
},
// 4. Sort & Pagination
{ $sort: { matchScore: -1 } },
{ $skip: offset },
{ $limit: limit }
];
Diese Pipeline läuft extrem schnell, da sie MongoDBs interne C++ Engine nutzt und Indizes (Compound Indexes auf skills.skillId und status) verwendet.
Daten, die sich selten ändern (wie die Liste aller Industrien, Rollen oder die Skill-Taxonomie), cachen wir im RAM via Redis.
// industries.service.ts
@Injectable()
export class IndustriesService {
constructor(@Inject(CACHE_MANAGER) private cacheManager: Cache) {}
async findAll() {
// Check Cache first
const cached = await this.cacheManager.get('all_industries');
if (cached) return cached;
// Database fallback
const industries = await this.industryModel.find().exec();
// Set Cache (TTL: 1 Stunde)
await this.cacheManager.set('all_industries', industries, 3600);
return industries;
}
}
Dies reduziert die Latency für statische Dropdown-Listen im Frontend von ~50ms auf ~2ms.
Der Bau der SkillScore API hat gezeigt, dass die Kombination aus NestJS und AI mächtige Werkzeuge für moderne HR-Tech-Lösungen sind.
Key Takeaways:
Die API ist nun in der Lage, Tausende von CVs täglich zu verarbeiten, Duplikate zu bereinigen und Recruitern die besten Matches in Echtzeit zu liefern. Der nächste Schritt? Die Integration von Vector-Datenbanken für semantische Suche, um nicht nur Keywords, sondern Bedeutungen zu matchen.
Möchten Sie den Code in Aktion sehen oder tiefer in die Implementierung einsteigen? Schauen Sie sich die interaktive Swagger-Dokumentation an oder besuchen Sie das GitHub Repo.
Dieser Artikel basiert auf dem echten Quellcode des CV Manager API Projekts, implementiert mit modernsten Best Practices für Node.js Backends.
Hier geht es zur Swagger UI API Dokumentation

Experte für digitale Produkte
Ich vereine User Research, Prototyping und TypeScript Frontend-/API-Entwicklung um exzellente digitale Lösungen zu gestalten.

Experte für digitale Produkte
Ich vereine User Research, Prototyping und TypeScript Frontend-/API-Entwicklung um exzellente digitale Lösungen zu gestalten.

Ich verwandle komplexe Anforderungen in elegante Lösungen.
oder anrufen +49 157 581 508 46+49 157 581 508 46